Why Your Quotes Are Slow and Your Data Reconciliation Is Manual (And How Insurers Fix It)
Insurance | May 7, 2026





Perceptive Analytics’ perspective: Most carriers treat slow quotes and manual reconciliation as operational nuisances — patched with a new hire or a point tool. At Perceptive Analytics, we view them as diagnostic signals of a deeper data architecture problem. When underwriters spend the majority of their day navigating disconnected systems, and finance teams are reconciling transactions manually at month-end, the root cause is almost never effort or skill. It is fragmented data that was never designed to serve decisions at the speed modern insurance operations require. The fix is not incremental. It requires rethinking how data moves, where it lives, and who owns its quality — before any automation layer is applied on top.
There is a particular kind of frustration that senior operations leaders in insurance know well. A broker submits a commercial lines risk on Monday. By Wednesday, the submission is still in a queue — not because your underwriters lack the skill to price it, but because the data they need lives in three different systems, two of which require a manual export before any analysis can begin. By Friday, the broker has placed the risk elsewhere.
The quote speed problem and the reconciliation problem look like two separate issues. They are not. Both trace back to the same structural condition: fragmented data, disconnected systems, and workflows designed around manual intervention rather than automated decision flows. The operational cost is quantifiable. According to Capgemini’s World Property and Casualty Insurance Report 2024, 41% of underwriters’ time is currently consumed by administrative and operational activities — not risk assessment, not broker relationships, not pricing judgment. Meanwhile, approximately 87% of insurance companies have encountered accounting-related challenges, yet only 15% have implemented substantial automation [ePayPolicy / Industry Survey, 2025] — a gap that explains why reconciliation teams are still manually matching transactions while the CFO waits for a clean financial close.
These are solvable problems. But solving them requires an honest diagnosis before any technology decision is made.
Struggling with slow quotes or manual reconciliation? Let’s map the root cause together.
Talk with our consultants today.
1. What Typically Slows Down Insurance Quote Turnaround?
The delay in getting a quote out the door rarely has a single cause. It is almost always a compounding sequence of smaller failures, each adding hours or days to a process that leading competitors are beginning to measure in minutes. For senior operations and distribution leaders, understanding where the compounding occurs is the precondition for any meaningful fix.
1. Submission data arriving in unusable formats
Brokers submit risks via email, spreadsheets, PDF attachments, and ACORD forms — rarely through structured digital intake. Someone on the underwriting team must manually rekey or interpret that data before pricing can begin. With AI-powered OCR, the same ACORD forms, loss runs, and certificates can be processed and mapped into management systems in under 30 minutes — a process that previously occupied two staff members for a full day [Insurance Support World, 2025].
2. First-in, first-out queuing without risk-based triage
Submissions are processed in the order they arrive, regardless of complexity, revenue potential, or strategic fit. A high-value account requiring 20 minutes of underwriter judgment sits in the same queue as a stack of standard risks that a rules engine could auto-quote. The sequencing problem is structural, not a capacity problem.
3. Underwriters navigating multiple disconnected systems
To assemble the data needed for a single pricing decision, underwriters move between policy administration, claims history, billing, and external risk data sources — none of which communicate directly. A 2025 Accenture report found underwriters devoted only 26% of their time to core underwriting tasks in 2024, down from 31% in 2021. The remaining 74% was largely absorbed by administrative navigation across systems.
4. Referral loops without structured workflow routing
Risks outside standard appetite require referral to senior underwriters, specialist teams, or reinsurance. Without structured routing, these referrals travel by email, sit in inboxes, and add days of avoidable latency — with no visibility for the submitting broker on where their risk stands or when to expect a response.
5. Inconsistent guideline application without a rules engine
Without automated appetite and rating logic, individual underwriters apply judgment inconsistently across similar risks. Non-standard submissions surface only during a manual review cycle rather than being flagged automatically at intake, creating downstream pricing inconsistency that erodes loss ratio over time.
2. How Leading Insurers Streamline Quote Processes for Speed
Carriers that have materially shortened quote turnaround times have consistently made three structural changes rather than one. None of these are primarily technology decisions — they are process and data architecture decisions that technology then executes.
Risk-based triage at intake. Intelligent triage separates straightforward, standard risks from complex or out-of-appetite submissions at the point of receipt. Standard risks flow directly to automated rating; complex risks are assigned to senior underwriters with all relevant data pre-populated. The outcome: high-value judgment work stays in human hands, and the routine work is removed from human queues entirely.
Straight-through processing (STP) for standard cases. STP — where a submission flows from intake through rating to quote issuance without manual intervention — is operationally achievable for a meaningful share of commercial and personal lines submissions. McKinsey analysis indicates more than 50% of claims activities have automation potential by 2030, with straight-through processing becoming standard for simple cases [McKinsey / Talli.ai, 2024]. The same logic applies to standard quote workflows, where STP rates of 40–60% are achievable on commodity risks with a properly configured rules engine.
Pre-underwriting data enrichment embedded at intake. Rather than asking underwriters to gather third-party data manually, leading carriers embed data enrichment into the intake workflow. External risk data — property characteristics, vehicle records, financial health scores, loss history — is pulled automatically and presented alongside the submission. Decisions are made on pre-assembled information rather than assembled on demand, compressing quote cycles and improving consistency.
Structured broker submission portals. Providing brokers with a digital portal that validates data at entry — rather than accepting unstructured email submissions — eliminates the manual interpretation step entirely. Brokers who experience consistent, fast turnaround from a structured portal place more business through it; the channel becomes a distribution retention mechanism.
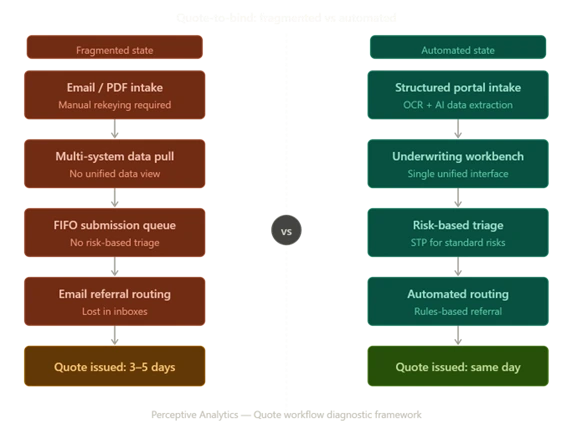
3. Technologies That Cut Quote Turnaround Times
No single tool resolves slow quoting. The most effective implementations combine several technology categories in a deliberate sequence:
| Technology | Core function | Direct impact on quote speed |
|---|---|---|
| Underwriting workbench | Unifies submission data, third-party enrichment, claims history, and rating into one interface | Eliminates multi-system navigation |
| Rules engine | Configurable appetite, eligibility, and rating logic | Enables STP for standard risks; enforces consistent referral routing |
| OCR / Document AI | Extracts structured data from ACORD forms, loss runs, PDFs | Eliminates manual rekeying at intake |
| API-connected external data | Real-time access to property databases, vehicle registries, credit scoring | Enriches submissions without underwriter intervention |
| Pricing analytics dashboards | Real-time loss ratio trends, segment performance, pricing adequacy monitoring | Enables pricing decisions from current data, not lagged quarterly reports |
Capgemini’s research confirms that an underwriting workbench implemented as a single unified platform over multiple legacy systems can significantly reduce manual data entry, minimise errors, and accelerate the full underwriting journey [Capgemini, 2024]. Power BI and Tableau are the most widely deployed platforms for those real-time pricing analytics dashboards — giving underwriting, product, and actuarial teams a live view of segment performance without data engineering bottlenecks. See Perceptive Analytics’ practical guide to sales and performance dashboards for applied examples of how this self-service analytics layer works in practice.
Perceptive’s POV — On Technology Sequencing: The instinct when faced with slow quote turnaround is to buy a tool. At Perceptive Analytics, we consistently find that carriers who deploy technology before redesigning the workflow beneath it achieve, at best, a faster version of a broken process. An underwriting workbench will not resolve a triage problem. A rules engine will not fix an inconsistent data model. The right sequence is: define the decision you are automating, standardise the data that feeds it, then select the technology that executes it. Tool selection is the final step, not the first.
4. Why Manual Data Reconciliation Is Draining Time and Money
Reconciliation — matching premium flows, claims payments, reinsurance settlements, and policy records across systems — is the invisible tax on insurance operations. It is not a glamorous problem, which is partly why it persists. But the financial drag is substantial and compounds with every period of inaction.
According to a 2024 Celent report, more than 70% of mid-tier insurers cite legacy billing systems as a barrier to operational efficiency, with manual reconciliations, disconnected payment channels, and limited visibility into receivables contributing directly to slower revenue recognition and higher administrative costs [Celent / Input1, 2024].
The structural reasons reconciliation remains manual are consistent across carriers:
1. Data silos with incompatible formats
Policy administration, billing, claims, and reinsurance systems were procured separately, often across different decades, and operate with different data models. Premium transactions recorded as “written” in one system may not match “earned” calculations in the actuarial system without manual conversion.
2. Batch processing creating inherent data latency
Most legacy environments update overnight or at week-end. By the time finance teams begin reconciliation, the underlying data is already hours or days old — and any discrepancy requires tracing back through multiple batch runs to locate the source.
3. No single authoritative record for core entities
Without master data management, the same policyholder, policy, or claim may carry different identifiers across systems. Matching records across sources requires manual judgment rather than automated key-matching logic.
4. Volume growth outpacing headcount
Premium volume grows; reconciliation team headcount does not scale proportionally. The result is a widening backlog that lengthens month-end close timelines and increases the risk of undetected errors reaching the financial statements — or the regulatory submission.
5. Tools and Platforms to Automate Data Reconciliation
The technology landscape for reconciliation automation is mature. The question is rarely whether a solution exists — it is which approach fits the organisation’s data architecture and integration requirements:
- Cloud data platforms (Snowflake, Databricks, Azure Synapse) — centralised analytical environments where policy, billing, and claims data are unified under a governed layer, enabling automated matching across sources that previously required manual cross-referencing. See Perceptive Analytics’ Snowflake data transfer case study for a live example of this approach applied at global scale.
- ETL/ELT and change data capture (CDC) tools — pipelines that stream changes from source systems in near real time, replacing batch overnight loads with continuous data synchronisation and eliminating end-of-day staleness. Talend is among the most widely deployed platforms for this in insurance environments, with proven connectors for policy administration, billing, and claims systems.
- Master data management (MDM) platforms — create golden records for policies, customers, and transactions, resolving duplicates and inconsistent records automatically so matching logic has clean, standardised inputs.
- Dedicated reconciliation engines (BlackLine, AutoRek, ReconArt) — purpose-built matching platforms applying configurable rules to transaction data across systems, flagging exceptions for human review rather than requiring line-by-line manual comparison.
- RPA (Robotic Process Automation) — software robots that navigate legacy system interfaces to extract, compare, and post reconciliation entries where full API connectivity is not yet available.
Some digital reconciliation solutions can save up to one hour of manual effort per transaction — a significant reduction when multiplied across thousands of premium and claims payments [One Inc, 2025]. For a worked example of how automated data extraction reduces manual effort at scale, see Perceptive Analytics’ real-time review insights case study.
The Reconciliation Maturity Model
A practical framework for assessing where your organisation sits today — and what the most achievable next step looks like:
| Maturity stage | Characteristics | Typical close timeline |
|---|---|---|
| Stage 1 – Manual | Spreadsheet-based matching, period-end only, high error rate | 10-14 working days |
| Stage 2 – Partially automated | Some automated matching, manual exception handling, batch feeds | 7-10 working days |
| Stage 3 – Integrated | API-connected systems, near-real-time feeds, exception-only human review | 3-5 working days |
| Stage 4 – Continuous | Automated reconciliation runs throughout the period; close is a validation, not a process | 1-2 working days |
Most mid-tier insurers sit at Stage 1 or Stage 2. Moving from Stage 2 to Stage 3 represents the highest-ROI transition available to most finance and operations leaders without a full core system replacement.
6. Business Case: Cost Savings from Automating Reconciliation
The financial case for reconciliation automation is consistently underbuilt in initial business cases because the costs of manual reconciliation are spread across headcount, error correction, delayed close cycles, and opportunity cost — rather than appearing as a single visible line item. Here is how to quantify each lever:
1. FTE hours redirected from matching to exception management
Financial institutions using workflow automation report a 30–50% reduction in operational costs for processes including account reconciliation and payment processing [Feathery, 2025]. In a 15-person reconciliation team, a 40% efficiency gain represents six FTEs that can be redeployed to higher-value analytical and control work without adding headcount.
2. Faster financial close — direct governance and revenue value
Month-end close timelines currently running 10–12 working days can compress significantly when reconciliation runs continuously rather than as a period-end manual exercise. Earlier close gives the CFO reliable financial data sooner, reduces the risk of material misstatements, and improves regulatory filing timelines.
3. Claims adjustment expense reduction
Firms with integrated claims and policy administration systems report up to a 25% reduction in claims adjustment expenses [Technavio, 2025]. A material share of this saving comes directly from eliminating manual data handling across the claims workflow — the same data fragmentation problem that drives reconciliation burden in the finance function. See how Perceptive Analytics’ operational data consolidation work reduces manual handling across high-volume transaction environments.
4. Regulatory reporting readiness without manual preparation
IFRS 17, Solvency II, and state-level regulatory requirements demand accurate, timely, and auditable financial data. Carriers with automated reconciliation environments produce regulatory submissions with significantly less manual preparation effort and with a defensible, system-generated audit trail.
5. Error rate reduction with direct financial impact
Manual reconciliation introduces transcription errors, missed matches, and posting errors that may not surface until audit — or until a regulatory review. Automated matching with systematic exception handling catches discrepancies earlier, more consistently, and with a full decision log that manual processes cannot replicate.
Perceptive’s POV — On Building the Business Case: The most common failure in reconciliation automation business cases is that the cost of doing nothing is invisible. Nobody writes a line item for “FTE time spent on spreadsheet matching” or “delay premium from a 12-day close cycle.” At Perceptive Analytics, we build reconciliation business cases by making these invisible costs explicit first — quantifying hours, error rates, and close timelines in current state — before projecting the automation benefit. When the baseline is honest, the ROI case is almost always stronger than the finance team expected. The challenge is not justifying the investment; it is being honest enough about the current state to see it clearly.
7. How Other Insurers Implement Automated Reconciliation (And What Can Go Wrong)
Successful implementations share a recognisable pattern. Carriers that struggle share a different one — specifically, the decision to automate before the underlying data quality and governance problems are resolved.
1. Conduct a data quality assessment before selecting a platform
Automation amplifies whatever is already in the data. If source systems contain duplicate records, inconsistent coding, or missing fields, automated matching will produce a high exception rate that overwhelms the efficiency gain. Treat identified data quality issues as pre-conditions for automation, not post-migration cleanup.
2. Define matching rules as a business exercise, not an IT exercise
The reconciliation engine needs explicit rules defining what constitutes a match — policy number, transaction date, premium amount, currency, and period. These rules require input from finance, actuarial, and operations leadership, not just the data engineering team. Skipping this step produces a system that technically runs but generates unacceptable exception volumes.
3. Run parallel operations during the transition period
Keep the legacy reconciliation process running alongside the automated environment until the new system has been validated over at least one full financial close cycle. Never decommission the manual process until automated output has been independently confirmed accurate against the legacy output.
4. Assign business ownership — not IT ownership — to the data domain
Effective data governance ensures that data is consistent, accessible, and discoverable across departments, cutting costs and improving productivity across functions [Atlan, 2024]. The finance director, not the data engineering team, should own the reconciliation data domain and be accountable for its quality.
5. Phase the rollout by transaction type
Begin with the highest-volume, most standardised transaction type — typically premium receipts or straightforward claims payments — where matching rules are simple and the efficiency gain is largest. Add complexity progressively as the team builds platform confidence.
6. Invest in change management for reconciliation staff
The transition from manual to automated reconciliation significantly changes job content. Staff who previously spent the majority of their time on mechanical matching need retraining for exception analysis, root cause investigation, and process improvement. This investment is consistently underbudgeted and consistently determines whether automation delivers its projected ROI.
7. Build controls and audit trails from day one
Automated reconciliation must produce a full audit log: what was matched, on what basis, and when. This is a regulatory and audit requirement, not an optional feature. Design for auditability at the architecture stage, not as a retrofit after go-live. Power BI implementation and Tableau implementation services can layer audit-ready dashboards on top of reconciliation data to give leadership and regulators the visibility they need.
Case Snapshot: Mid-Market P&C Carrier — Reconciliation Transformation
A mid-market property and casualty carrier processing commercial lines was running a 12-day month-end close, with a 10-person reconciliation team spending approximately 70% of their time on manual transaction matching across three disconnected systems — policy administration, billing, and claims. After implementing a cloud data platform with an MDM layer to create golden records, and a dedicated reconciliation engine for automated matching, the carrier reduced its close timeline to four working days. Five FTEs were redeployed from matching to analytical roles supporting finance and actuarial. The exception rate — transactions requiring human review — fell from approximately 35% to under 8%, and the automated audit trail satisfied regulatory reviewers without supplemental manual documentation.
The sequence — data quality first, golden records second, automated matching third — is the pattern Perceptive Analytics applies consistently across reconciliation modernisation engagements.
Case Snapshot: Commercial Lines Carrier — Quote Turnaround Improvement
A mid-market commercial lines carrier with three separate underwriting systems was unable to generate a consistent quote without manual data pulls from each. After implementing a unified underwriting workbench with API-connected external data enrichment and a pre-configured rules engine, the carrier achieved STP rates of approximately 55% on standard commercial auto and property risks within six months of go-live. Average quote turnaround on those segments dropped from four days to same-day. The underwriting team redeployed its capacity to complex and high-value accounts — improving pricing adequacy and broker service on the risks that matter most commercially.
Perceptive’s POV — On Implementation Risk: The biggest risk in a quote or reconciliation automation programme is not technical — it is organisational. The technical problems have known solutions. The organisational risks — business units that refuse to commit to a canonical data model, data stewards who do not engage, executives who approve the investment but do not protect the timeline — are harder to manage and more likely to cause failure. Executive sponsorship that includes accountability for governance, not just budget approval, is what separates programmes that deliver from those that linger.
8. Next Steps: Where to Start with Quote and Reconciliation Improvements
The twin problems of slow quotes and manual reconciliation share a common solution path: better data foundations, clearer process ownership, and automation applied in the right sequence.
Step 1 – Map Before You Automate
Conduct a structured process mapping exercise for both the quote workflow and the reconciliation workflow. Where does data enter? Where is it handled manually? Where do delays and errors concentrate? This exercise consistently surfaces two or three high-impact interventions implementable quickly — before any major platform investment is made.
Step 2 – Run a Data Quality Baseline
Before selecting a reconciliation platform or an underwriting workbench, assess the quality of the data those tools will consume. Completeness, accuracy, consistency, and timeliness across policy, billing, and claims data determines whether automation delivers its projected benefits — or industrialises an existing data problem.
Step 3 – Pilot on One High-Volume, Standardised Workflow
Resist the temptation to transform everything simultaneously. Choose one quote segment and implement STP end to end. Or choose one transaction type for automated reconciliation and run it alongside the manual process until validated. Insurers can expect a 40% productivity increase after a successful data platform transformation [Intellias, 2025]. That return begins with the discipline to fix one workflow properly before expanding to the next.
For related reading on how data-driven analytics transforms operational workflows, see Perceptive Analytics’ resources on inventory optimization and data-driven distribution and our guide to securing data in Power BI dashboards — both directly applicable to the governance and access-control requirements of insurance reconciliation environments.
Sources & References
[1] Capgemini (2024). World P&C Insurance Report 2024.
[2] Accenture / Unqork (2025). AI Underwriting Workbench.
[3] ePayPolicy / Industry Survey (2025).
[4] McKinsey / Talli.ai (2024).
[5] Insurance Support World (2025).
[6] Feathery (2025).
[7] Celent / Input1 (2024).
[8] One Inc (2025).
[9] Technavio (2025). Claims Processing Software Market Analysis.
[10] Atlan (2024).
[11] Intellias (2025).
[12] Deloitte (2025–26). 2026 Global Insurance Outlook.
Ready to fix your quote turnaround and close your reconciliation gap?
Talk with our consultants today.