The 6-9 Month Data Layer: Modernizing P&C Intelligence Without Core Disruption
Insurance | April 9, 2026





The Gap Between AI Ambition and Data Reality
Here is the uncomfortable truth facing mid-market P&C carriers today: 67% acknowledge modernization as essential, yet 86% remain dissatisfied with their analytics capabilities [Source: BriteCore 2025 P&C Core Systems Report]. Over 60% are piloting AI, but fewer than 15% have successfully scaled it across core operations [Source: Guidewire]. That gap is not a technology problem. It is a data architecture problem.
Across data modernization programs we’ve analyzed, this is a pattern we see repeatedly: organizations invest in AI tools that sit on top of fragile, siloed data, only to watch them underdeliver. P&C insurance is no different. The fix is not a three- to five-year core replacement. It is a targeted data layer modernization that takes six to nine months.
While our direct work in P&C is evolving, the patterns we’re seeing closely mirror what we’ve implemented in other data-heavy industries like banking, retail, and pharma, where fragmented data ecosystems create the same upstream drag on AI adoption. In banking, for instance, we built an ML-powered look-alike model that achieved a 450% improvement in targeting effectiveness and a 50% conversion rate. These outcomes became possible only once the underlying data layer was clean and unified. This post walks through exactly how that same foundation-first logic applies to P&C carriers today.
Q: Why does AI fail in P&C insurance? Because it’s applied on top of fragile, siloed data. Over 60% of carriers are piloting AI, but fewer than 15% have successfully scaled it — the bottleneck is almost always the data layer, not the model itself. |
Why “Bolt-On AI” Fails
Many carriers attempt to layer AI on top of legacy cores, chatbots on policy systems, fraud detection on claims databases, and pricing models on rating engines. This creates what we call patchwork AI: point solutions that solve narrow problems while multiplying long-term complexity.
Each new AI initiative demands custom integrations, data extracts, and reconciliation processes. Technical debt compounds with every deployment. The root cause is simple: AI cannot deliver value when core platforms cannot supply clean, contextual, real-time data. Fixing the AI is not the answer. Fixing the data layer is.
The shift from hindsight to action is accelerating. Customers, brokers, and partners now expect instant quotes, immediate claims updates, and proactive risk management. As we have explored in depth on our insurance analytics practice page, the carriers closing this gap are not the biggest — they are the most architecturally nimble.
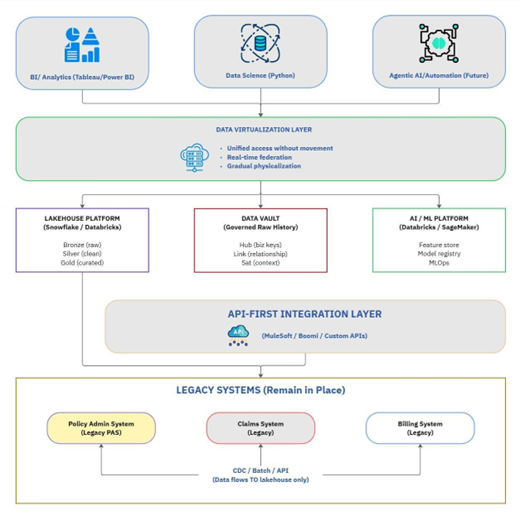
The 6–9 Month Path: What It Actually Means
The 6–9 month timeline is achievable only when the scope is correctly defined. It is data layer modernization, not core system replacement. The distinction matters enormously.
What this approach delivers:
- A cloud-native lakehouse (Snowflake, Databricks, or equivalent) sitting alongside existing systems
- AI-ready data pipelines with real-time feeds from policy, claims, billing, and external sources
- A unified analytics layer powering underwriting, claims, and executive dashboards
- API-first integration that wraps legacy systems without replacing them
What it does not include: full Policy Administration System replacement, custom software built from scratch, or “boiling the ocean” re-architecture. When those boundaries hold, the timeline holds.
Industry examples show what this looks like in practice. When Arch Insurance migrated nine source systems from legacy SQL Server to Snowflake using an agile, parallel approach, issue resolution time dropped from two days to hours with zero downtime. Separately, GAINSCO cut state launch time from 15 months to 16 weeks using cloud-native platforms [Source: Duck Creek customer case study]. These patterns are well-documented across the industry — and they closely mirror what we see in data modernization programs more broadly: the right foundation, not a core replacement, is what unlocks speed.
The 90-Day Foundation Sprint
The first 90 days are about building credibility and infrastructure in parallel. Perceptive Analytics structures this as three bi-weekly phases:
Weeks 1–4 — Assess and provision:
- Inventory all source systems: policy, claims, billing, CRM, external feeds
- Assess API readiness and current data quality across domains
- Stand up a cloud environment with dev, test, and production tiers
Weeks 5–8 — First data in:
- Extract from the highest-value source system (typically policy or claims)
- Load to a bronze layer—raw, unmodified—and implement Change Data Capture for near-real-time updates
- Automate data profiling: completeness, uniqueness, business rule validation
Weeks 9–12 — First dashboards live:
- Underwriting performance: quote volume, bind rate, premium by line
- Claims severity trends: loss development, emerging patterns, reserve adequacy
- Customer 360: policy count, claims history, relationship depth
The goal of the sprint is not perfection. It is demonstrable progress that builds the internal case for continued investment. As we wrote in our piece on how high-performing insurers rebuilt their analytics workflows, the carriers that succeed move fast on a scoped foundation rather than waiting for perfect source data.
Q: What does data layer modernization actually include? A cloud-native lakehouse, AI-ready data pipelines, a unified analytics layer, and API-first integration that wraps and not replaces, your existing core systems. The goal is operational intelligence within 90 days, not a full platform overhaul. |
What Intelligence-Ready Looks Like at Month 6
Months four through six transition from infrastructure to operational intelligence. The goal is to embed analytics into daily workflows, not just building dashboards.
Three AI use cases are typically sequenced based on where margin pressure is most acute:
- Automated Submission Triage: AI classifies submissions by complexity and appetite alignment. Target: 30% straight-through processing, 50% reduction in quote turnaround.
- Fraud Detection: Real-time claim scoring at first notice of loss. Target: 20% improvement in detection rate, 15% reduction in false positives.
- Next-Best-Action for Retention: A predictive model flags policies at risk of non-renewal and recommends interventions. Target: 5-point improvement in retention rate.
The sequencing matters. If underwriting capacity is the bottleneck, start with triage. If the loss ratio is the concern, lead with fraud detection. If renewal rates are slipping, retention modeling comes first. Most carriers pursue all three over 12–18 months—but starting in the right place accelerates early ROI.
Understanding why decision speed is now the primary competitive variable in insurance is a key focus of our analysis of decision velocity as the new metric for insurers. The carriers pulling ahead are not necessarily the largest — they are the ones that close the loop between data and action fastest.
The Seven Traps That Kill Modernization Projects
McKinsey research puts the failure rate for large-scale data transformations at around 70% [Source: McKinsey]. From what we’ve observed across data modernization programs, most of these failures trace back to a predictable set of mistakes:
- Technology-first thinking: Building infrastructure before defining the three to five use cases it needs to solve
- Big-bang replacement: Attempting full core conversions instead of the strangler-fig approach of building alongside legacy
- Data perfectionism: Waiting for clean data before delivering value—the antidote is 80% quality today, improving incrementally
- Siloed AI pilots: Fraud, pricing, and claims experiments running independently with no shared data foundation
- Architecture-AI mismatch: Deploying agentic AI on batch-oriented infrastructure that cannot support real-time queries
- “Tech-washing”: New UI on old systems masking underlying data debt—this destroys M&A valuations
- Underestimating integration: APIs and data pipelines are not simple—they require dedicated resources and iPaaS tooling
The human side of these failures is something we address directly in our perspective on why speed must still serve judgment in insurance analytics. Automation accelerates the right decisions only when the underlying data is trustworthy and the governance is sound.
Q: How long does it realistically take to modernize a P&C insurer’s data layer? Six to nine months for a targeted data layer modernization, not a core replacement. McKinsey puts the failure rate for large-scale data transformations at 70%, most of which trace back to scope overreach. Keeping the scope to the data layer, not the core, is what makes the timeline hold. |
The Time to Build Is Now
The P&C combined ratio is expected to reach 99% in 2026 [Source: Swiss Re]. At that margin, there is no room for delayed decisions, manual reconciliation, or siloed AI experiments. The carriers that modernize their data layer now will have dynamic pricing, real-time claims intelligence, and embedded insurance capabilities ready when the embedded insurance market hits its projected 35.14% CAGR through 2030 [Source: Research and Markets].
From where Perceptive Analytics sits, the question is not whether to modernize—it is whether you do it now on your terms or reactively under pressure from competitors who already have. If you want to understand what an intelligence-ready P&C operation looks like in practice, our deep-dive on how AI is rewiring the insurance claims process is a good place to start. And if you are ready to map your own 90-day sprint, talk to our insurance analytics team.
The companies that lead are not the ones that score risk the best—they are the ones that operationalise intelligence fastest.
— Perceptive Analytics
Not sure where your data layer is breaking down?
We’ll help you identify the fastest path to operational intelligence.
Book a consultation.
Frequently Asked Questions
Why does AI fail in P&C insurance companies?
AI fails in P&C insurance primarily because it’s deployed on top of fragile, siloed data infrastructure rather than a clean, unified data layer. Over 60% of carriers are piloting AI, yet fewer than 15% have successfully scaled it across core operations. The bottleneck is almost never the AI model itself — it’s the inability of core platforms to supply clean, contextual, real-time data. Each bolt-on AI initiative requires custom integrations and data extracts, compounding technical debt with every deployment.
How long does it take to modernize a P&C insurer's data layer?
A targeted data layer modernization — not a full core system replacement — can be completed in 6 to 9 months. This timeline is achievable when the scope is correctly defined: building a cloud-native lakehouse, AI-ready data pipelines, a unified analytics layer, and API-first integrations that wrap (not replace) legacy systems. McKinsey estimates a 70% failure rate for large-scale data transformations; most failures trace back to scope overreach, which is why keeping the project focused on the data layer is critical.
What is the difference between data layer modernization and core system replacement?
Core system replacement involves rebuilding or swapping out Policy Administration Systems and other foundational platforms — a multi-year, high-risk undertaking. Data layer modernization, by contrast, builds a cloud-native analytics infrastructure (such as Snowflake or Databricks) alongside existing systems using API-first integration. It delivers AI-ready data pipelines and unified dashboards without touching the core. This approach significantly reduces risk and compresses timelines from years to months.
What does a 90-day data modernization sprint look like for P&C carriers?
A 90-day sprint typically runs in three bi-weekly phases. Weeks 1–4 focus on assessing all source systems — policy, claims, billing, CRM — evaluating API readiness and data quality, and provisioning a cloud environment with dev, test, and production tiers. Weeks 5–8 focus on extracting from the highest-value source system, loading to a raw bronze layer with Change Data Capture for near-real-time updates, and automating data profiling. Weeks 9–12 deliver the first live dashboards covering underwriting performance, claims severity trends, and customer 360 views.
What are the most impactful AI use cases for P&C insurance carriers?
Three AI use cases consistently deliver the strongest early ROI for P&C carriers: (1) Automated submission triage, which uses AI to classify submissions by complexity and appetite alignment, targeting 30% straight-through processing and a 50% reduction in quote turnaround time. (2) Real-time fraud detection at first notice of loss, targeting a 20% improvement in detection rate and 15% reduction in false positives. (3) Next-best-action models for retention, which flag at-risk policies and recommend interventions, targeting a 5-point improvement in renewal rates. Sequencing these based on where margin pressure is most acute accelerates early ROI.
What are the most common reasons P&C data modernization projects fail?
What cloud platforms are best suited for P&C insurance data modernization?
Cloud-native lakehouse platforms — Snowflake and Databricks are the most widely adopted — are the primary infrastructure layer in modern P&C data modernization. Arch Insurance’s migration of nine source systems from legacy SQL Server to Snowflake using an agile, parallel approach resulted in issue resolution dropping from two days to hours with zero downtime. GAINSCO reduced state launch time from 15 months to 16 weeks using cloud-native platforms. These platforms support both structured insurance data and the unstructured feeds needed for AI model training.
Why are mid-market P&C carriers struggling with analytics despite significant investment?
According to BriteCore’s 2025 P&C Core Systems Report, 67% of mid-market carriers acknowledge modernization as essential, yet 86% remain dissatisfied with their analytics capabilities. The core issue is that analytics investments are often layered on top of siloed, fragmented data — point solutions that solve narrow problems while compounding long-term complexity. Without a unified data foundation, every new analytics initiative requires custom data extracts and reconciliation processes, making it impossible to scale insights across underwriting, claims, and finance simultaneously.
What business outcomes should P&C carriers expect from data layer modernization?
Within six to nine months, carriers can expect operational intelligence embedded across underwriting, claims, and executive workflows — not just dashboards. Specific benchmarks from documented implementations include a 450% improvement in targeting effectiveness from ML-powered models built on unified data, 30% straight-through processing in submission triage, 20% improvement in fraud detection rates, and a 5-point gain in policy retention rates. The broader strategic benefit is decision velocity — closing the loop between data and action faster than competitors.
How does the P&C combined ratio outlook affect the urgency of data modernization?
The P&C combined ratio is projected to reach 99% in 2026, according to Swiss Re. At that margin, operational inefficiencies — delayed decisions, manual reconciliation, siloed AI experiments — become existential rather than merely costly. Simultaneously, the embedded insurance market is projected to grow at a 35.14% CAGR through 2030, which will heavily favor carriers with dynamic pricing, real-time claims intelligence, and API-first integration already in place. Carriers that delay data modernization risk being structurally unable to compete in the next product generation.