Why AI/ML Workflows Are Breaking Traditional Data Platforms
AI | April 16, 2026





Designing AI-ready systems without destabilizing analytics foundations
Executive Summary
AI/ML workflows introduce real-time processing, feature engineering, and new storage paradigms that traditional data platforms were not designed to handle. Most organizations respond by adding new systems, creating silos and governance gaps.
A warehouse-centric architecture, combined with event-driven pipelines and unified observability, enables AI adoption without fragmenting the platform. The result is faster model deployment, lower operational overhead, and stronger governance across both analytics and ML.
Is your data platform ready to support AI/ML workflows without creating new fragmentation?
Talk with our consultants today. Book a session with our experts now.
AI/ML Workflows Fail When They Bypass the Data Platform
A Perceptive Analytics POV
At Perceptive Analytics, we consistently observe that AI/ML initiatives struggle not because of modeling complexity, but because they operate outside the data platform’s governance and design principles. Feature stores, vector databases, and real-time pipelines are often introduced as independent systems, leading to duplicated logic, inconsistent data definitions, and rising operational costs.
The organizations that succeed take a platform-first approach. They anchor feature engineering in the warehouse, extend data through controlled streaming pipelines, and ensure that ML workflows inherit the same governance, lineage, and quality standards as analytics. This approach allows AI to scale without introducing fragmentation or technical debt.
AI/ML Workflows Are Creating Invisible Fragmentation Across the Platform
AI does not break platforms through a single architectural decision. It fragments them gradually through repeated local optimizations made by different teams. What begins as an attempt to enable faster experimentation often results in multiple parallel systems that solve similar problems in slightly different ways. Over time, this creates a platform that is technically functional but operationally inefficient and strategically misaligned.
The fragmentation typically shows up in four forms. Our article on moving from data fragmentation to AI performance through unified architecture explains how these patterns compound — and what the architectural path out of them looks like.:
Feature Logic Divergence
The same business definition such as customer lifetime value or churn risk is recreated across notebooks, pipelines, and dashboards. Each version evolves independently, leading to inconsistent outputs across the organization.Uncontrolled Data Replication
Features and datasets are copied into feature stores, vector databases, and inference layers. This increases storage cost, pipeline complexity, and synchronization overhead.Latency-Driven Architecture Decisions
To support real-time inference, teams bypass batch pipelines and create new streaming paths that are faster but disconnected from governance frameworks.Disconnected Tooling Ecosystem
ML workflows rely on separate tools for tracking, monitoring, and deployment, making it difficult to establish end-to-end lineage or accountability.
This pattern mirrors what we see in analytics platforms when architectural discipline is absent. Infrastructure scales, but value does not scale proportionally. With AI/ML, this imbalance becomes more pronounced because both data movement and experimentation increase simultaneously. Our piece on static pipelines as an enterprise liability explores why rigid, unmonitored pipeline architectures are the structural root of this problem and why it accelerates as AI workloads are added on top.
A Unified Architecture Model That Aligns Analytics and AI/ML Workflows
| Layer | Traditional Analytics Design | AI/ML-Driven Reality | Unified Architecture Principle |
|---|---|---|---|
| Data Foundation | Warehouse as reporting layer | Multiple feature stores emerge | Warehouse as system of record for features |
| Transformation | Batch ETL pipelines | Real-time feature engineering | Hybrid batch + streaming pipelines |
| Data Movement | Scheduled data loads | Continuous event streams | CDC and event-driven synchronization |
| Serving Layer | Dashboards and reports | APIs, embeddings, inference endpoints | Controlled serving layers derived from warehouse |
| Governance | Strong lineage and controls | Fragmented across ML tools | Unified observability across analytics and ML |
| Cost Structure | Predictable compute usage | Explosive due to duplication | Minimize copies and redundant pipelines |
What this model reinforces is simple but critical: AI/ML does not require a separate platform. It requires extending the existing one with new capabilities while preserving control. Our guide on future-proof cloud data platform architecture maps the design decisions that make this extension sustainable as AI workloads grow.
A Practical 5-Step Framework to Design AI/ML-Ready Data Platforms
Define the Warehouse as the Feature Authority
All features used in models must originate from the warehouse. This ensures consistency between what is measured in dashboards and what drives model predictions. SQL and dbt become the standard for feature definition, not optional tools. Our comparison of Airflow vs. Prefect vs. dbt for data orchestration explains how these tools work together to enforce this warehouse-first discipline across both analytics and ML pipelines.Introduce Event-Driven Extensions, Not Parallel Pipelines
Instead of building separate pipelines for ML systems, use CDC and streaming to propagate features from the warehouse to downstream systems like vector databases or caches. This keeps the source logic centralized.Implement Feature Versioning as a Governance Layer
Every feature should be version-controlled, documented, and traceable. This allows teams to reproduce models, audit decisions, and avoid rebuilding logic repeatedly.Unify Orchestration Across Data and ML Workflows
Tools like Airflow and dbt should orchestrate both data pipelines and model workflows. Dependencies between data freshness, feature availability, and model retraining must be enforced programmatically.Expand Observability to Include Model and Feature Behavior
Monitoring should go beyond pipeline health to include feature drift, model performance, and data quality across both analytics and ML systems.
Organizations that implement this framework reduce operational overhead while improving model reliability and deployment speed. More importantly, they avoid creating a fragmented ecosystem that becomes difficult to scale.
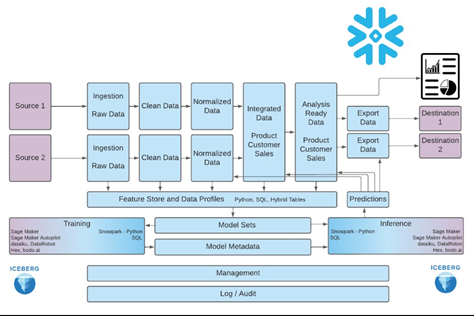
Reference: Infostrux Engineering Blog
Why Observability Becomes the Control Layer for AI/ML at Scale
As AI/ML workflows expand, observability evolves from a monitoring function to a control mechanism for the entire platform. Traditional observability focuses on pipeline failures and data quality. AI introduces additional dimensions such as feature drift, model degradation, and inference reliability.
Without integrating these into a unified framework, organizations lose visibility into how decisions are being made. At Perceptive Analytics, we recommend extending observability across three layers. Our advanced analytics consultants implement this three-layer model as a standard component of every AI platform engagement:
Data Layer
Lineage, freshness, and quality checks across all pipelines.Feature Layer
Distribution shifts, feature stability, and version tracking.Model Layer
Performance metrics, drift detection, and retraining triggers.
This unified approach ensures that governance is not diluted as AI adoption scales. It also enables faster root cause analysis, as issues can be traced across the full lifecycle from raw data to model output.
FAQs: What CXOs Need to Clarify Before Scaling AI/ML Workflows
Do we need a separate feature store?
Only when latency requirements demand it. Otherwise, the warehouse can serve as the primary feature store with downstream synchronization.Will AI/ML disrupt existing analytics systems?
Not if designed as an extension of the platform rather than a parallel system.How do we control infrastructure costs?
By minimizing data duplication, reducing redundant pipelines, and aligning architecture with actual latency requirements. Our article on controlling cloud data costs without slowing insight velocity provides the cost governance model that applies directly to AI/ML infrastructure spend.What is the biggest architectural risk?
Fragmentation caused by independently evolving ML systems outside governance boundaries.
Conclusion
AI/ML workflows are reshaping data platforms at a structural level. Organizations that treat them as extensions of analytics maintain control, consistency, and scalability. A warehouse-centric design, unified orchestration, and shared observability prevent fragmentation while enabling innovation.
At Perceptive Analytics, we help enterprises build AI-ready platforms that scale without compromising governance or efficiency. The next step is to assess whether your platform can support AI/ML workflows without breaking and partner with Perceptive Analytics to turn that assessment into a production-ready, scalable AI advantage.
Our AI consulting practice is built around exactly this transition: from fragmented experimentation to governed, enterprise-scale AI delivery.
Ready to build an AI-ready data platform that scales without fragmenting your analytics foundation?
Talk with our consultants today. Book a session with our experts now.
Frequently Asked Questions
Do AI/ML workflows require a separate feature store?
Not unless extreme latency demands it. Use your warehouse as the primary feature authority with downstream event-driven sync to vector databases, ensuring consistency without duplication or silos.
How do AI/ML workflows fragment traditional data platforms?
Through feature logic divergence, uncontrolled data replication, latency-driven bypasses of batch pipelines, and disconnected ML tooling leading to inconsistent outputs, higher costs, and governance gaps across analytics and AI.
Can a warehouse-centric architecture support both analytics and AI/ML?
Yes, by defining the warehouse as the system of record for features, adding hybrid batch/streaming pipelines via CDC, and unifying orchestration with tools like dbt and Airflow for scalable, governed workflows.
What are the biggest risks of bypassing the data platform for AI/ML?
Duplicated logic, rising storage/inference costs, fragmented observability, and technical debt that slows model deployment and erodes trust in analytics outputs.
How can organizations control infrastructure costs in AI/ML platforms?
Minimize data copies with warehouse-derived serving layers, align pipelines to real latency needs, and implement unified observability to cut redundant compute avoiding explosive duplication from parallel systems.
What role does observability play in AI/ML-ready data platforms?
It evolves into a control layer covering data lineage, feature drift, model performance, and retraining triggers enabling end-to-end traceability and faster issue resolution across analytics and ML.